
Overview
Big Data Lake Testing ensures that large-scale data processing systems handle high-volume, high-velocity, and high-variety data accurately and efficiently. It validates ingestion, storage, transformation, and querying layers within modern data lake architectures.
Key Testing Strategies
1. Data Validation
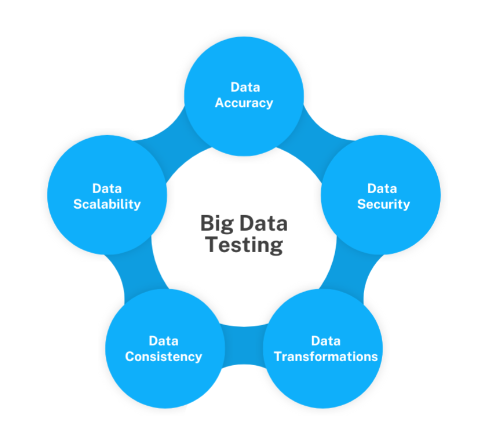
Validate completeness, accuracy, consistency, and correctness of data across ingestion and transformation layers.
2. Performance Testing
Measure the system’s performance under massive data loads, ensuring optimal processing time and throughput.
3. Integration Testing
Validate the seamless interaction between data ingestion pipelines, processing engines, and storage layers.
4. Security Testing
Ensure data access protocols, encryption mechanisms, and permissions are correctly implemented to prevent breaches.
5. Scalability Testing
Assess the system’s ability to scale automatically (or manually) based on increasing data and processing demands.
Benefits
- Improved data accuracy and reliability across big data systems
- Enhanced performance and scalability under large workloads
- Early detection of data quality or system performance issues
- Increased confidence in analytics and reporting outcomes
Use Cases
- Data ingestion pipeline validation
- Real-time streaming data platform testing
- Data warehouse and data lake ecosystem validation
- IoT and sensor data analytics validation